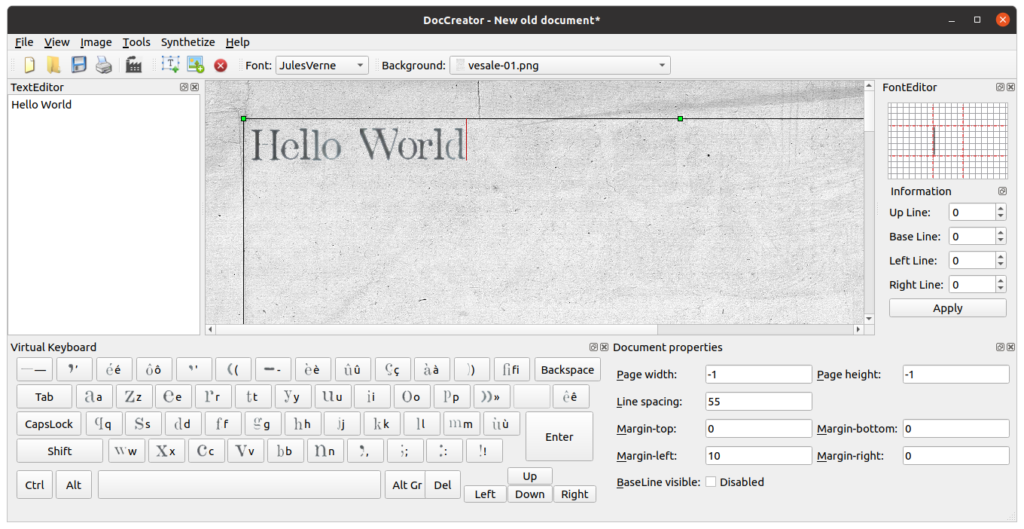
DocCreator is a program for producing synthetic ground-truth documents, designed to help you generate a larger dataset for training more robust deep learning models. It’s a WYSIWYG editor, a bit like Word for making digitized old documents.
In this article we’ll examine some of its features and the effects it produces on documents.
Motivation
People have recorded information on paper for hundreds of years. Since the rise of mechanical printing, this has been much easier to do than by hand, and over time more and more people were able to encode their thoughts, ideas, and business in text.
Nowadays, there’s simply too much paper. Printed documents have been the primary medium of data storage for most businesses for decades. All of this information is effectively locked away; retrieving data from text is, compared to searching a digital database, extremely slow and error prone. Someone first has to find the relevant document, which is often no small task. Then they must either scan it and send an image of the result or read it and type it out into another document and send that for possible editing. Typos and misreadings are all too frequent.
With the rise of machine learning, new technologies are being developed to alleviate this burden. In particular, we now have algorithms for Optical Character Recognition (OCR), which can turn an image of a document into a text file, where the text corresponds to whatever was written on the document.
These algorithms need to be trained, however, in much the same way a person would learn to read: they need to see a lot of examples of text and be given “ground truth” – that is, someone has to tell them what it’s all supposed to say. You’d use DocCreator or another data augmentation tool to produce such a body of images and associated text.
Why DocCreator?
If you’re already looking to perform data augmentation work, and particularly degrading images of documents while preserving ground truth, there are a few reasons you’d want to choose DocCreator over alternatives:
The Graphical Interface
Part of what makes DocCreator such an interesting project is that the developers have provided a GUI to drive the behavior. If you’re using off-the-shelf ML models and don’t want to write code to produce images, this will be really appealing. I’ll go through a bit of using the interface a little later in this post.
The Outputs
DocCreator can produce documents that look incredibly realistic. The background images they include are high-resolution scans of old manuscripts with different paper textures, and there are similarly old-style fonts to write with.
3D Documents
The DocCreator authors used a 3D scanner to map a collection of real documents, and built an interface into the program allowing you to apply a 2D document image to the surface of those 3D models. The first time I used this, I was blown away by how real the result looked. You can test the 3D editor on the web here.
Setup
There are several ways to get DocCreator on your own machine, and a demo of the 3D editor is even available online.
I don’t have a Windows or Mac machine to test on, and at time of writing, the Dockerfile was unavailable, so I cloned the GitHub repository and built the software manually.
Using the Interface
However you get the software installed, when you start up the editor, you’ll see something similar to popular word processors, with a centered viewing area, and a real-time representation of the document.
Once you click the button to add a text block, an outlined field appears on the page in the viewing pane, and it becomes possible to enter text in the left pane.
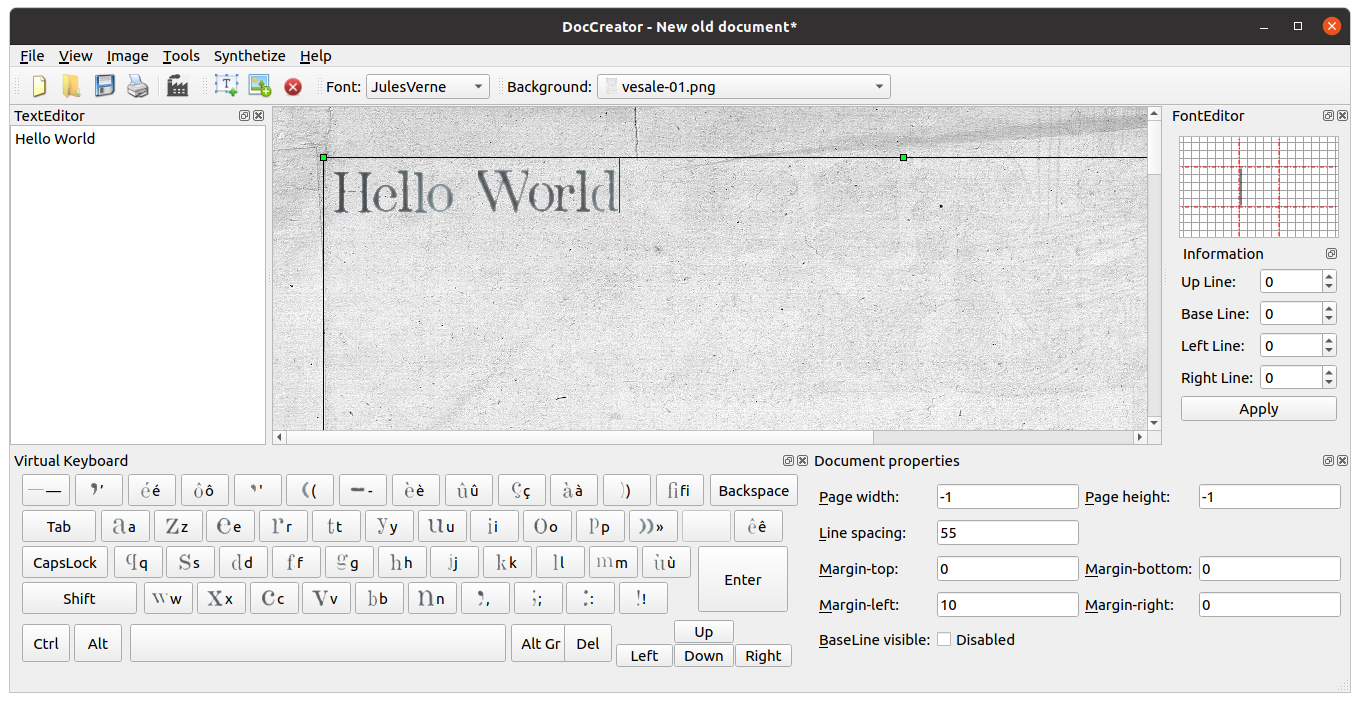
An on-screen keyboard at the bottom of the window displays characters you can enter, dependent on the current font selected in the top panel. If you use your physical keyboard, this will light up to indicate the key you’re pressing. The keyboard has the AZERTY layout; the authors of the software are French.
Different built-in page backgrounds and fonts can be selected from the top panel, though changing the font doesn’t seem to change more than the characters visible on the virtual keyboard and the mapping to characters you input with the physical keyboard. Really this is more like changing keyboard layouts.
The most important function is a little factory icon in the toolbox; this button opens a wizard that guides you through setting up a batch job to generate synthetic (from a text string) or semi-synthetic (from an existing image) documents with several kinds of image degradation applied.
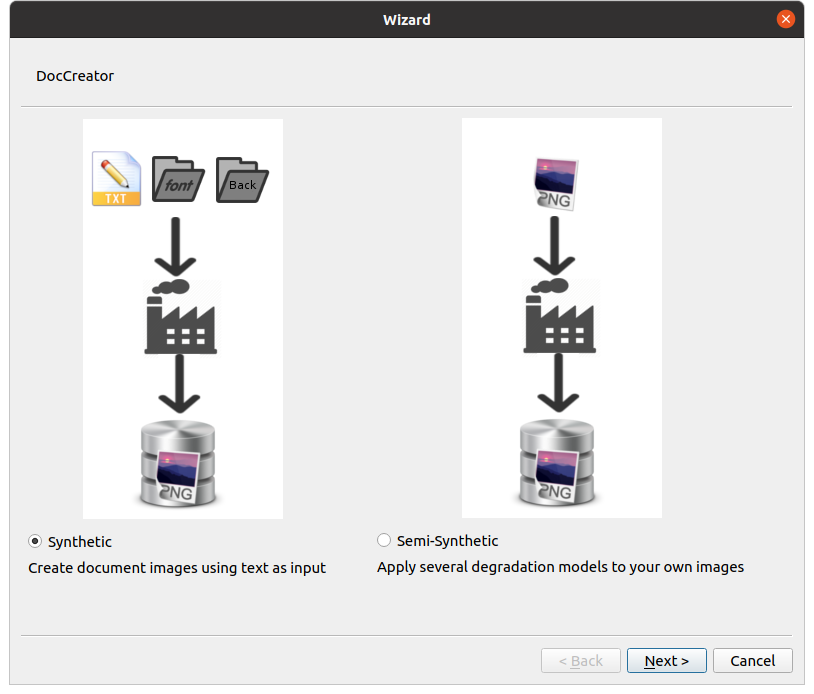
Let’s take a look at some now.
Degradations
The primary feature in any data augmentation library is its suite of degradations, or transformations that alter the input material to produce new output data. DocCreator is no different in this respect and includes a decent range of image transforms that produce realistic outputs. Here are some of the most striking:
Bleed-Through
This degradation simulates ink from the reverse side of the page becoming visible on the front.

ShadowBinding
When you open a book and place it in a scanner bed, the pages curl up towards the book’s binding, and the scan result shows gradual darkening in that region of the page as the distance from the scanner bed increases. This degradation produces the same effect.

HoleDegradation
Old manuscripts are often physically missing pieces; this degradation mimics a hole in the document material.

GradientDomainDegradation
People generally don’t treat their documents well almost as a rule, but old documents in particular have had a lot of time to pick up stains. This degradation adds stains of varying sizes, intensities, and quantities throughout the document, simulating years of use.

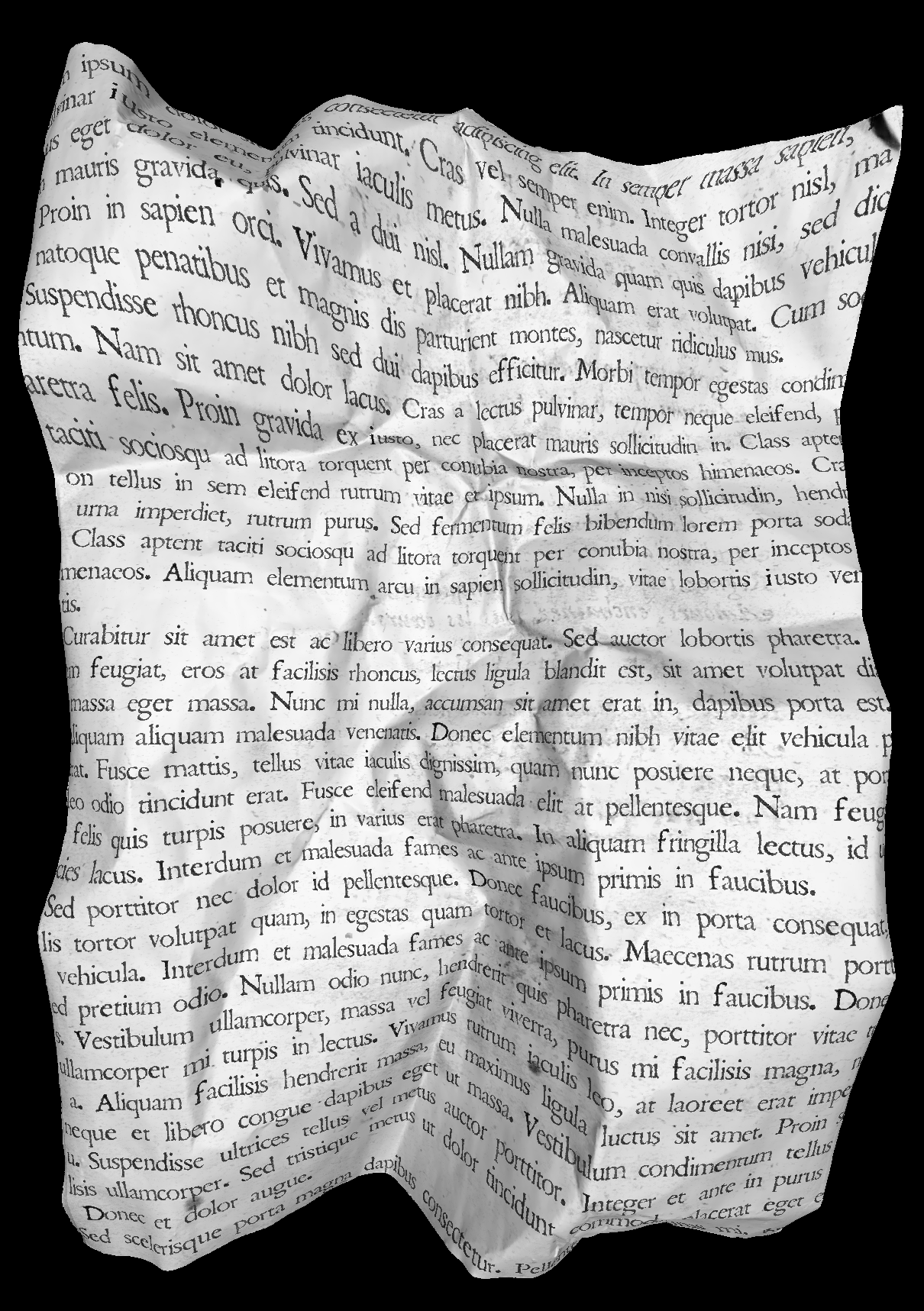
3D distortion
This is, in my opinion, by far the coolest degradation. The authors have scanned documents with a 3D scanner, created 3D skeletons from the scan results, and given us a way of mapping our 2D document to the surface of the 3D object, simulating various physical deformations that can occur to documents.
Ground Truth
To train a model, a set of “ground-truthed” inputs must be provided, which give the model a unit of data (an image, a video, some text, etc.) and the intended interpretation of that data. In our case, the ground truth for a synthetic document generated with DocCreator is stored as an XML file in the same directory as the image. This file contains a full specification of the document, including the background image (the paper on which the document was “printed”), the font style, and a record of where each character is located in the image. Algorithms use this information in their training phase to determine what they’re looking at, and essentially learn to read the kind of data they’re training on.
Here’s what a ground-truth file looks like:

Because DocCreator generates these along with the document, you can be sure that you always have a record of what images should say, even if those images are later distorted by various transformations. By keeping this record, you can help your algorithm learn to read more accurately, even from heavily damaged documents.
Takeaways
DocCreator is a really cool project that I’ll be watching closely from now on. What they’ve been able to achieve so far is amazing, especially considering they produced an entire GUI dedicated to this toolkit. The documents you can produce entirely within the software look extremely realistic, and the 3D rendering was a neat touch.
I did run into some issues using the software, however. There were minor UX problems like graphical glitches or unclear menu labels, but I also encountered several bugs that crashed the program.
There currently doesn’t seem to be a way to use DocCreator in headless mode via a scripting interface, but hopefully this is added in a future release.



